This messy note is for me to learn.
date:显示日期who:用来获取当前登陆到系统的用户们的信息
The tty number is a unique identification number the Unix system gives to each terminal or network device that a user is on when they log into the system.
who am i:echo:不论你是用多个空格分割word它还是用一个空格来帮你分隔word
ls:listing filesls with -l option provides a more detailed description of the files in a directory.
Each successive line displayed by the ls -l command contains detailed information about a file in the directory.The first character on each line indicates what type of file it is: d for a directory, - for a file, b, c, l, or p for a special file.
The next nine characters on the line define the access permissions of that particular file or directory. These access modes apply to the file’s owner(the first three characters), other users in the same group as the file’s owner (the next three characters), and finally all other users on the system(the last three characters).
cat:displaying the contents of a file.
wc:counting the number of word s in a file,With the wc command, you can get a count of the total number of lines, words,and characters contained in a file.(换行也算是一个characters)
cp:To make a copy of a file.
mv:To move or rename a file. Be careful! When executing an mv or cp command, the Unix system does not care whether the file specified as the second argument already exists.
rm:To remove a file from the system. note:the -r is useful option
..:always references the directory that is one level higher than the current directory, known as the parent directory.
.:always refers to the current directory.
pwd:Is used to help you “get your bearings” by telling you the name of your current working directory.
cd: change your current working directory.
mkdir:To create directories.
ln:To creates a new directory entry (linked file) which has the same modes as the original file. note:the -s is useful option
rmdir:To remove a directory.
ed: Is a line-oriented text editor. In the ed editor, regular expression sequences such as *, ., [...], $, and ^ are only meaningful in the search string and have no special meaning when they appear in the replacement string. If a caret ^ appears as the first character after the left bracket, the sense of the match is inverted. (By comparison, the shell uses the ! for this purpose with character sets.) For example, the regular expression [^A-Z] matches any character except an uppercase letter. Similarly, [^A-Za-z] matches any non-alphabetic character.
Filename Substitution:*:The Asterisk matches zero or more characters.?:The question mark matches exactly one character. note: Another way to match a single character is to give a list of characters to match within square brackets[].
You can also specify a logical range of characters with a dash, a huge convenience! The only restriction is specifying a range of characters is that the first character must be alphabetically less than the last character, so that [z-f] is not a valid range specification, while [f-z] is.
If the first character following the [ is a !, the sense of the match is inverted. That is, any character is matched except those enclosed in the barckets.*[!o]
for examples:ls [a-z]*[!0-9] List files that begin with a lowercase letter and don’t end with a digit.
\:using backslashes to denote that the special character is part of the filename.
Standard Input/Output, and I/O Redirection
Ctrl+d:That is used to terminate the input is not counted as a separate line by the wc command because it’s interpreted by the shell, not handed to the command.
>:known as output redirection
>>:This character pair causes the sandard output from the command to be appended to the contents of the specified file.The previous contents are not lost.the new output simply gets added to the end.
<:Used to redirect the input of a command.
|:It enables you to take the outpt from one command and feed it directly into the unput of another.
Filters
Is refer to any program that can take input from standard unput, perform some operation on that input, and write the results to standard output.
Standard Error
How to distinguish standard error and standard output?
You can verify that this message is not being written to standard output by redirecting the ls command’s output.ls n* > foon* not found
As you can see, the message is still printed out at the terminal and was not added to the file foo, even though you redirected standard output.
So that error messages will still get displayed at the terminal even if standard output is redirected to a file or piped to another command.2>:redirect standard error to a file.
;:You can type more than one command on a line provided that you separate them with a semicolon.
&:Sending a Command to the Background. When a command is ent to the background, the Unix system automatically displays two numbers. The first is called the command’s job number and the second the process ID, or PID.
ps: The ps command gives you information about the processes running on the system. Without any options, it prints the status of just your processes.
The ps command prints out four columns of information:PID, the process ID; TTY, the terminal number that the process was run from; TIME, the amount of computer time in minutes and seconds that process has used; and CMD, the name of the process.
note: When used with the -f option, ps prints out more information about your processes, including the parent process ID (PPID), the time the process started (STIME), and the command arguments:
The shell’s responsibilities
- program execution
- The shell is responsible for the execution of all programs that you request from your terminal.
Each time you type in a line to the shell, the shell analyzes the line and then determines what to do. As far as the shell is concerned, each line follows the same basic format:
program-name arguments
The line that is typed to the shell is known more formally as the command line. The shell scans this command line and determines the name of the program to be executed and what arguments to pass to the program.
The shell uses special characters to determine where the program name starts and ends, and where each argument starts and ends. These characters are collectively called whitespace characters, and are the space character, the horizontal tab character, and the end-of-line character, known more formally as the newline character. Multiple occurrences of whtespace characters are ignored by the shell. When you type the commandmv tmp/mazewars games
the shell scans the command line and takes everyting from the start of then line to the first whitespace character as the name of the program to execute:mv. Subsequent whitespace (the extra spaces) are ignored and the set of characters up to the next whitespace character is the first argument to mv:tmp/mazewars. The charracters up to the next whitespace character–in this case, the newline character–is the second argument to mv:games. After parsing the command line, the shell then proceeds to execute the mv command, giving it the two specified arguments tmp/mazewars and games
We mentioned earlier that the shell searches the disk until it finds the program you want to execute and then asks the Unix kernel to initiate its execution. This is true most of the time. However, there are some command s that are actually built into the shell itself. These built-in commands includecd,pwd, andecho. Before the shell searches the disk for a command, it first determines whether it’s a built-in command, and if so executes the command directly.
But there’s a bit more the shell does before individual programs are invoked.
- variable and filename substitution
- Like a more formal programming language, the shell lets you assign values to variables. Whenever you specify one of these variables on the command line preceded by a dollar sign, the shell substitutes the value assigned to the variable.
The shell also preforms filename substitution on the command line. In fact, the shell scans the command line looking for filename substitution characters*,?, or[...]before determining the name of the program to execute and its arguments.echo *file1 file2 file3 file4
How many arguments were passed to the echo program, one of four? Because the shell performs the filename substitution, the answer is four. When the shell analyzes the lineecho *
it recognizes the special character*and substitutes the names of all files in the current directory.(it even alphabetizes them for you)
- I/O redirection
- It is also the shell’s responsibility to take care of input and output redirection. It scans each entered command line for occurrences of the special redirection characters
<,>, or>>wc -l < usersand
Because no filename was specified, wc decides that the number of lines coming in from standard input should be counted instead. Sowc -lcounts the number of lines, unaware that it’s actually counting the number of lines in the file users. The final tally is displayed as usual, but without the name of a file because wc wasn’t given one.
- pipeline hookup
- Just as the shell scans the command line looking for redirection characters, it also looks for the pipe character
|. For each match, it connects the standard output from the preceding command to the standard input of the subsequent one, then initiates execution of both programs.
- environment control
- The shell provides certain commands that let you customize your environment. Your environment includes your home directory, the characters that the shell displays to prompt your to type in a command, and a list of the directories to be searched whenever you request that a program be executed.
- interpreted programming language
- The shell has its own built-in programming language. Thislanguage is interpreted, meaning that the shell analyzes each statement as encountered, then executes any valid commands found. This differs from programming languages like C++ and Swift, in which the prgramming statements are typically compiled into a machine-executable form before they are executed. Programs developed in interpreted programming languages are typically easier to debug and modify than compiled ones. However, they can take longer to execute than their compiled equivalents.
The shell prgramming language provides features you’d find in most other programming languages. It has looping constructs, decision-maring statements, variables, and functions, and is procedure-oriented. Modern shells based on the IEEE POSIX standard have many other features including arrays, data typing, and built-in arithmetic operations.
Tools of the Trade
Regular Expressions
Regular expressions are used by many different Unix commands, including ed, sed, awk, grep, and to a more limited extent, the vi editor. They provide a comvenient and consistent way of specifying patterns to be matched.
Matching Any Character: The Period
.ed intro1,$s/p.o/XXX/g
The prefix1,$indicate that it should be applied to all lines in the file, and the substitution is specified with the structrues/old/new/g, where s indicates it’s a substitution, the slashes delimit the old and new values, and g indicates it should be applied as many times as needed for each line, not just once per line.Matching the Beginning of the Line: The Caret
^
When the caret character^is used as the first character in a regular expression, it matches the beginning of the line.ed intro /^the/ # Find the line that starts with the 1,$s/^/>>/ # Insert >> at the beginning of each line 1,$p # Print the first line to the last lineMatching the End of the Line: The Dollor Sign
$
Just as the^is used to match the beginning of the line, so the dollar sign $ is used to match the end of the line. So the regular expression contents$ matches the characters contents only if they are the last characters on the line. Note:^$which matchies any line that contains no characters at all. Note that this regular expression is different form^$which matches any line that consists of a single space character./\.$/ #Search for a line that ends with a period 1,$s/..$// #Delete the last two characters from each lineMatching a Character Set: The
[...]ConstructCharacter/[the]/ /[tT]he/Matching Zero or More Characters: The Asterisk
*
The asterisk is used by the shell in filename substitution to match zero or more characters. In forming regular expressions, the asterisk is used to match zero or more occurrences of the preceding element of the regular expression (which may itself be another regular exression).X* # matches zero, one, two, three, ... capital X's XX* # matches one or more capital X's, because the expression specifies a single X followed by zero or more X's. You can accomplish the same effect with a + instead: it matches one or more of the preceding expression, so XX* and X+ are identical in function..*: Is often used to specify zero or more occurrences of any charcters. Bear in mind that a regular expression matches the longest string of characters that match the pattern. Therefore, used by itself, this regular expression always matches the entire line of text.
As another example of the combination of.and*, the regular expressione.*ematches all the characters from the first e on a line to the last one. Note that it doesn’t necessarily match only lines that start and end with an e, however, because it’s not left- or right-rooted (that is, it doesn’t use^or$in the pattern).Matching a Precise Number of Subpatterns:
\{...\}
In the preceding examples, you saw how to use the asterisk to specify that one or more occurrences of the preceding regular expression are to be matched. For instance, For instance, the regular expressionXX*means match an X followed by zero or more subsequent occurrences of the letter X. Similarly,XXX*means match at least two consecutive X’s.
Once you get to this point, however, it ends up rather clunky, so there is a more general way to specify a precise number of characters to be matched:by using the construct\{min,max\}
where min specifies the minimun number of occurrences of the preceding regular expression to be matched, and max specifies the maximum. Notice that you need to escape the curly brackets by preceding each with a backslash.
The regular expressionX\{1,10\}
matches from one to 10 consecutive X’s. Whenever there’s a choice, the largest pattern is matched.
As another example, the regular expression[A-Za-z]\{4,7\}
matches a sequence of alphabetic letters from four to seven characters long.
Here is the example
`ed intro
1,$s/[A-Za-z]{4,7}/Q/g
1,$p
The Q Qng Q was Qed by Ken Qn and Q Q at Q QQ
in the Q 1960s . One of the Q Q in
the Q of the Q Q was to Q an QQ Q Qd Qnt Q QQ.
-11 22333 44
22- Q-`
If only one number is enclosed by braces, as in \{10\} that number specifies that the preceding regular expression must be matched exactly that many times.
- Saving Matched Characters:
\(...\)
It is possible to reference the characters matched against a regular expression by enclosing those characters inside backslashed parentheses. These captured characters are stored in pre-defined variables in the regular expression parser called registers, which are numbered 1 through 9.
As a first example, the regular expression^\(.\)matchies the first character on the line, whatever it is, and stores it into register 1.
To retrieve the characters stored in a particular register, the construct\nis used, where n is a digit from 1 to 9. So the regular expression^\(.\)\1initially matches the first character on the line and stores it in register 1, then matches whatever is stored in register 1, as specified by the\1. The net effect of this regular expression is to match the first two characters on a line if they are both the same character.
Successive occurrences of the\(...\)construct get assigned to successive registers. So when the following regular expression is used to match some text^\(...\)\(...\)the first three characters on the line will be stored into register 1, and the next three characters into register 2. If you appended \2\1 to the pattern, you would match a 12-character string in which characters 1-3 matched characters 10-12, and in which characters 4-6 matched characters 7-9.就是:1-3的字符和10-12的字符是一样的,4-6的字符和7-9的字符是一样的,当时没看明白这句话是什么意思。多看几眼居然明白了!
When using the substitute command in ed, a register can also be referenced as part of the replacement string, which is where this can be really powerful:ed phonebook1,$s/\(.*\) \(.*\)/\2\1/ #Switch the two fields
The names and the phone numbers are separated from each other in the phonebook file by a single tab character.
summarizes the special characters recognized in regular expressions to help you understand any you encounter and so you can build your own as needed.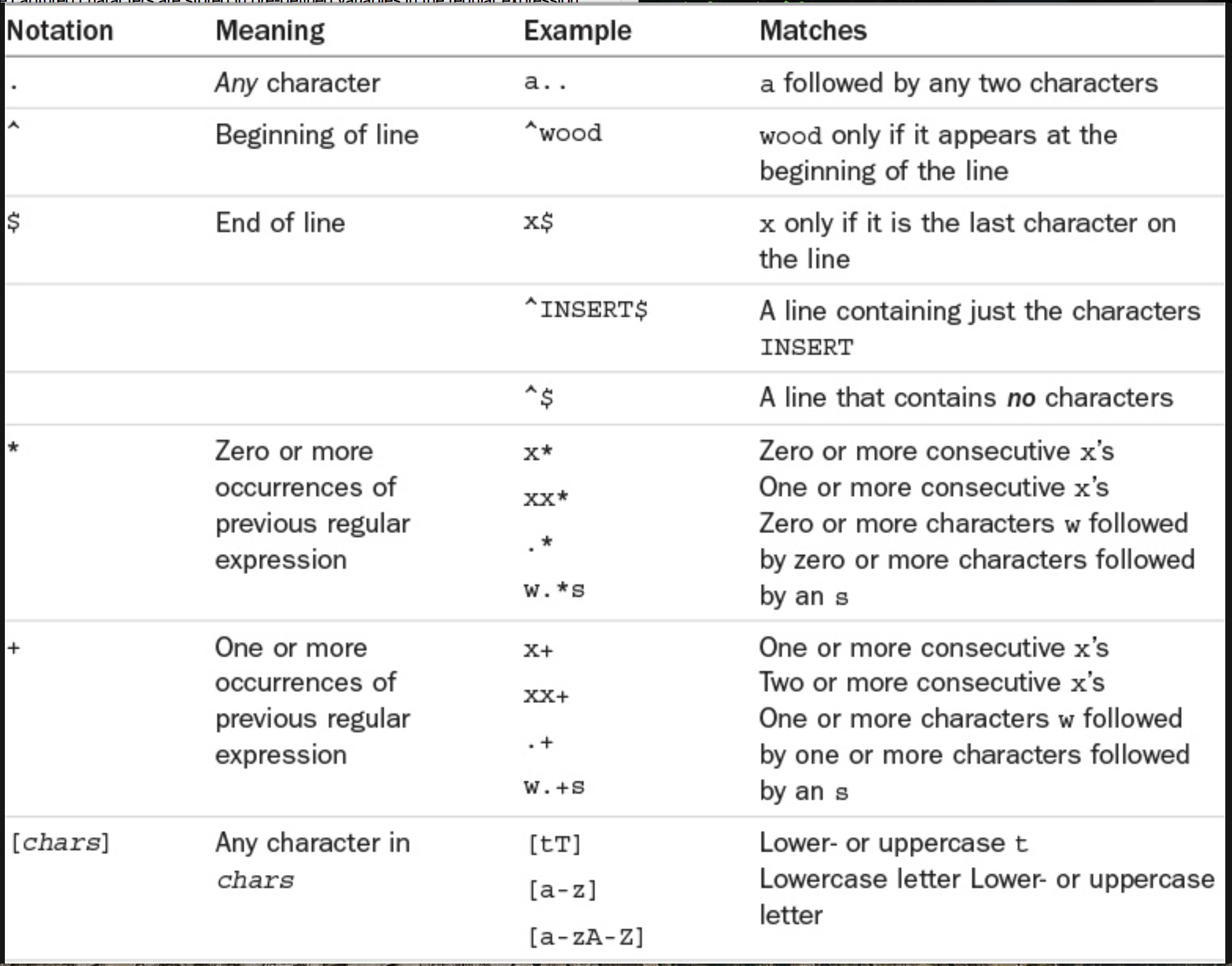

Useful command: cut, paste, sed, tr, grep, sort, uniq
cut: this command comes in handy when you need to extract (that is, “cout out”) various fields of data from a data file or the output of a command. The general format of the cut command iscut -cchars filewhere chars specifies which characters (by position) you want to extract from each line of file. This can consist of a single number, as in -c5 to extract the fifth character from each line of input; a comma=separated list of numbers, as in-c1,13,50to extract characters 1, 13, and 50; or a dashseparated range of numbers, as in -c20-50 to extract characters 20 through 50, inclusive. To extract characters to the end of the line, you can omit the second number of the range socut -c5- dataextracts characters 5 through the end of the line from each line of data and writes the results to standard output.
If file is not specified, cut reads its input from standard input, meaning that you can use cut as a filter in a pipeline.
You can use cut to extract as many different characters from a line as you want. Here, cut is used to display just the username and login time of all logged-in users:who | cut -c1-8,18-
The-dand-fOptions
The-dand-foptions are used withcutwhen you have data that is delimited by a particular character, with-dspecifying the field seperator delimiter and-fthe field or fields you want extracted. The invocation of thecutcommand becomescut -ddchar -ffields filewhere dchar is the character thant delimits each field of the data, and fields specifies the fields to be extracted from file. Field numbers start at 1, and the same type of formats can be used to specify field numbers as was used to specify character positions before (for example,-f1,2,8;-f1-3;-f4-).
If thecutcommand is used to extract fields from a file and the-doption is not supplied,cutuses the tab character as the default field delimiter. In a sutuation where the fields are separated by tabs, you should use the-foption to cut instead.
How do you know in advance whether fields are delimited by blanks or tabs? One way to find out is by trial and error, as shown previously. Another way is to type the commandsed -n l fileat your terminal. If a tab character separates the fields,\twill be dispalyed instead of the tab.paste:Thepastecommand is the inverse ofcut: Instead of breaking lines apart, it puts them together. The general format of thepastecommand ispaste fileswhere corresponding lines from each of the specified files are “pasted” or merged together to form single lines that are then written to standard output. The dash character-can also be used in the files sequence to specify that input is from standard input.
The-dOptions
If you don’t want the output fields separated by tab characters, you can specify the-doption to specify the output delimiter:-dcharswhere char is one or more characters that will be used to separate the lines pasted together.That is, the first character listed in chars will be used to separate lines from the first file that are pasted with lines from the second file;the second character listed in chars will be used to separate lines from the second file from lines from the third, and so on.
If there are more files than there are characters listed in chars, paste “wraps around” the list of characters and starts again at the beginning.
Notice that it’s always safest to enclose the delimiter characters in single quotes.
The-sOption
The-soption tells paste to paste together lines from the same file, not from alternate files. If just one file is specified, the effect is to merge all the lines from the file together, separated by tabs, or by the delimiter characters specified with the-doption.ls | paste -d'' -s -: the output from ls is piped to paste which merges the lines (-soption) from standard input (-), separating each field with a space (-doption).sed: is a program used for editing data in a pipe or command sequence. It stands for steam editor. Unlike ed, sed cannot be used interactively, though its commands are similar. The general form of the sed command issed command filewhere command is an ed-style command applied to each line of the specified file. If no file is pecified, standard input is assumed.
As sed applies the indicated command or commands to each line of the input, it writes the results to standard output.
Get into the habit of enclosing your sed command in single quotes.
Note that sed makes no changes to the original input file.
By appending the global optiongto the end of the substitute commands, you can ensure that multiple occurrences on a line will be changed.sed 's/Unix/UNIX/g' file > file1
The-nOption
By default,sedwrites each line of input to standard output, whether or not it gets changed. Sometimes, however, you’ll want to usesedjust to extract specific lines from a file. That’s what the-nflag is for: it tellssedthat you don’t want it to print any lines by default. Paired with that, use thepcommand to print whichever lines match your specified range or pattern.
For example, to print just the first two lines from a file:sed -n '1,2p' introIf, instead of line numbers, you precede the p command with a sequence of characters enclosed in slashes, sed prints just the lines from standard input that match that pattern.sed -n '/UNIX/p' introto display just the lines that contain a particular string.
To delete lines of text, use the d command.sed '1,2d' intro.sed '/UNIX/d' introto delete all lines of text containing the word UNIX.
Table 1.2.0 shows some more examples of sed commands.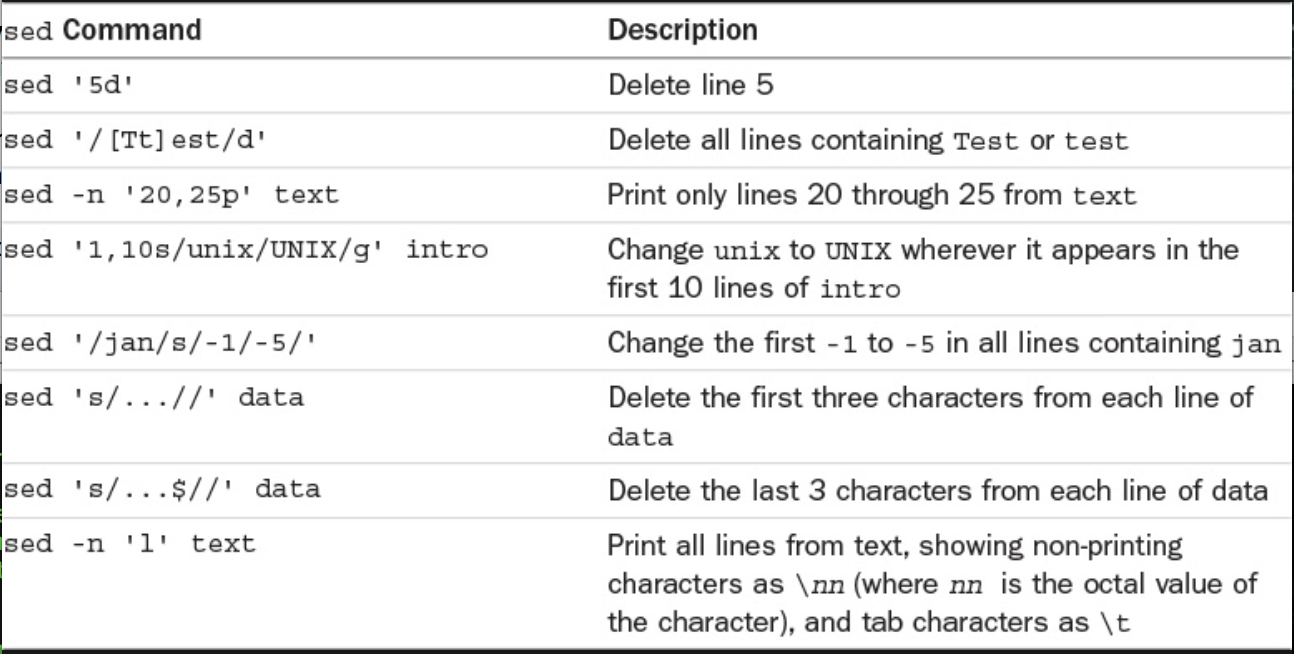
tr: The tr filter is used to translate characters from standard input. The general form of the command istr from-chars to-charswhere from-chars and to-chars are one or more characters or a set of characters. Any character in from-chars encountered on the input will be translated into the correspinding character in to-chars. The result of translation is written to standard output.
The input to tr must be redirected from the file becausetralways expects its input to come from standard input. The results of the translation are written to standard output, leaving the original file untouched.
Working with characters that aren’t printable? The octal representation of a character can be given to tr in the format\nnnwherennnis the octal value of the character. This isn’t used too often, but can be handy to remember.
Table 1.3.0 lists characters that you’ll often want to specify in octal format.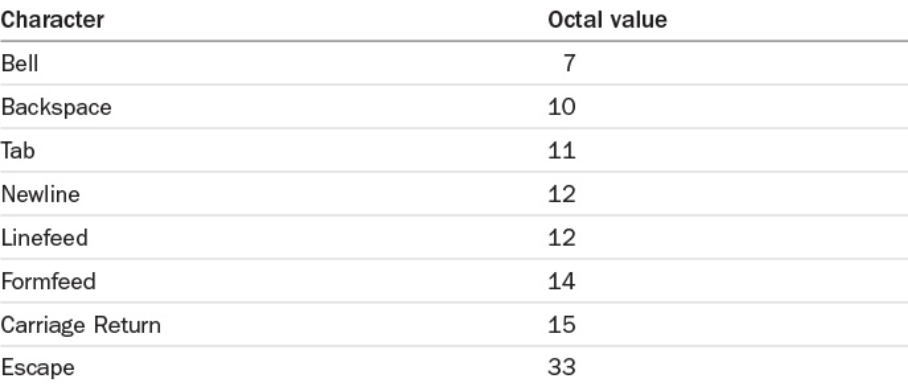
date | tr ' ' '\12'tr '[a-z]' '[A-Z]' < intro Figured it out?
The -s Option
You can use the -s option to “sequeeze” out multiple consecutive occurrences of characters in to-chars. In other words, if more than one consecutive occurrence of a character specified in to-chars occurs after the translation is made, the characters will be replaced by a single character.
Note that \t can work in many instances instead of \11, so be sure to try that if you want things to be a bit more readable!
The -d Optiontr can also be used to delete individual characters from the input stream. The format of tr in this case is tr -d from-chars
Note: Bear in mind that tr works only on single characters. So if you need to translate anything longer than a single character (say all occurrences of unix to UNIX), you have to use a dirrerent program, such as sed, instead.
Table 1.4.0 summarizes how to use tr for translating and deleting characters.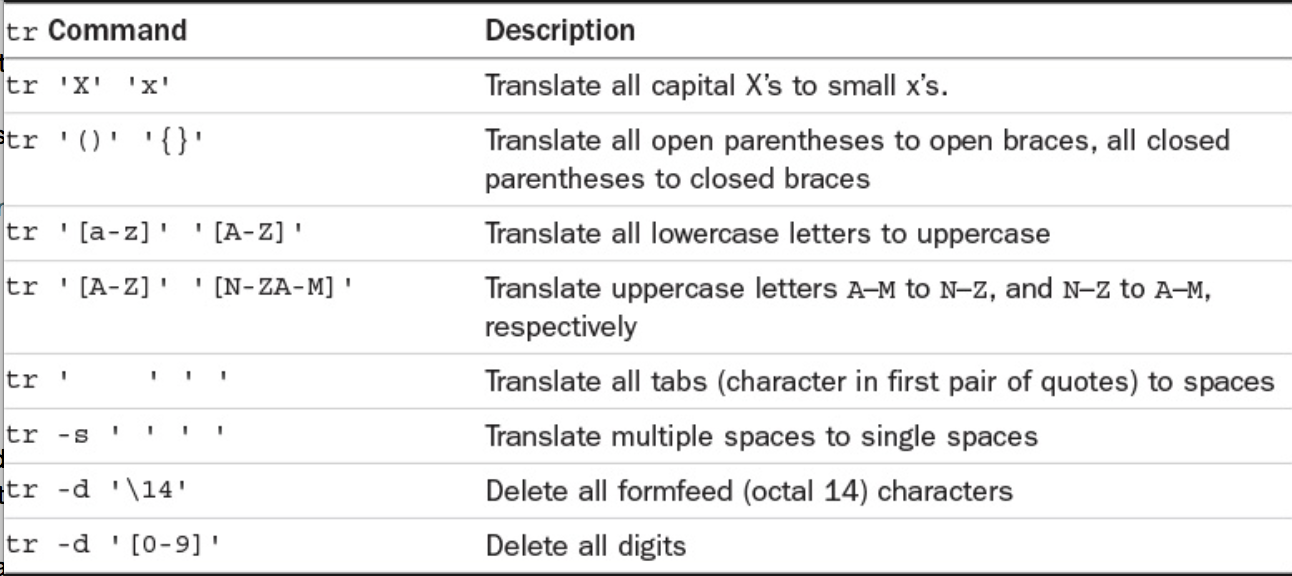
grep: grep allows you to search one or more files for a pattern you specify. The general format of this command isgrep pattern files. Every line of each file that contains pattern is displayed at the terminal.
Whengrepis executed, it interprets the first argument as the search pattern and the remaining arguments as the names of the files to search.
If more than one file is specified to grep, eacn line is also preceded by the name of the file, thus enabling you to identify the particular file that the pattern was found in.
Regular Expressions and grep
grep allows you to specify your pattern using regular expressions as in ed.
The-ioption : makes patterns case insensitive.
The-voption: to reverse the logic of the matching task.
Sometimes you’re interested not in finding the lines that contain a specified pattern, but those that don’t. That’s what the-voption is for with grep.
The-loption: to grep and you instead get a list of files that contain the specified pattern, not the matching lines from the files. At times, you may not want to see the actual lines that match a pattern but just seek the names of the files that contain the pattern.
The-noption: If the-noption is used with grep, each line from the file that matches the specified pattern is preceded by its corresponding line number.sort: give it lines of input and it’ll sort them alphabetically.
By default, sort takes each line of the specified input file and sorts it into ascending order.
Special characters are sorted according to the internal encoding of the characters.
The-uoption: tells sort to eliminate duplicate lines from the output.
The-roption: to reverse the order of the sort.
The-ooption: specify the output file. Frequently, you want to sort the lines in a file and have the sorted data replace the original. But typingsort files > fileswon’t work, —it ends up wiping out the files file! However, with the-ooption, it is okay to specify the same name for the output file as the input file.
The-noption: specifies that the first field on the line is to be considered a number, and the data is to be sorted arithmetically.
Skipping Fields
If you had to sort your data file by the y value-that is, the second number in each line-you could tell sort to start with the second field by using the option-k2ninstead of-n. The-k2says to skip the first field and start the sort analysis with the second field of each line.
The-toption: if you skip over fields, sort assumes that the fields are delimited by space or tab characters. The-toption can indicate otherwise.sort -k3n -t: /etc/passwduniq: The uniq command is useful when you need to find or remove duplicate lines in a file. The basic format of the command isuniq in_file out_fileIn this format, uniq copies in_file to out_file, removing any duplicate lines in the process. uniq’s definition of duplicated lines is consecutive lines that match exactly.
If out_file is not specified, the results will be written to standard output. If in_file is also not specified, uniq acts as a filter and reads its input from standard input.
The-doption: It tells uniq to write only the duplicated lines to out_file (or standard output). Such lines are written just once, no matter how many consecutive occurrences there are.eg, you just interested in finding just the duplicate entries in a file.
Other Options
The-coption to uniq adds an occurrence count, which can be tremendously useful in scripts.
“check out Awk—A Pattern Scanning and Processing Language, by Aho, et al., in the Unix Programmer’s Manual, Volume II for a description of awk, and Learning Perl and Programming Perl, both from O’Reilly and Associates, offering a good tutorial and reference on the language, respectively.”
Commnad Files
A shell program can be typed directly, or it can be typed into a file and the file can be executed by the shell.
Whenever the shell encounters the special character #, it ignores whatever characters appear starting with the # through to the end of the line. If the # starts the line, the entire line is treated as a comment.
Variables: Like virtually all programming languages, the shell allows you to store values into variables. A shell variable begins with an alphabetic or underscore _ character and is followed by zero or more alphanumeric or underscore characters. Note: Keep that in mind, especially if you’ve worked in other programming languages and you’re in the habit of inserting spaces around oprators. In the shell language, you can’t put those spaces in. Second, unlike most other programming languages, the shell has no concept of data types. Whenever you assign a value to a shell variable, no matter what it is, the shell simply interprets that value as a string of characters.
The $ character is a special character to the shell when followed by one or more alphanumeric characters. If a variable name follows the $, the shell takes this as an indication that the value stored inside that variable is to be substituted at that point.
Undefined Variables Have the Null Value.
The ${variable} Construct: This removes any ambiguity.
Built-in Integer Arithmetic
The POSIX standard shell as included with all modern Unix and Linux variants (including Mac OS X’s command shell) provides a mechanism for performing integer arthmetic on shell variables called arithmetic expansion.
The format for arithmetic expansion is $((expression)) where expression is an arithmetic expression using shell variables and operators. Valid shell variables are those that contain numeric values (leading and trailing whitespace is allowed). Valid operators are taken from the C programming language and are listed in IEEE Std 1003.1-2001.
Note:
$(()) Operators
There is a surprisingly extensive list of operators, including the basic six:+,-,*,/,% and **, along with more sophisticated notations including +=,-=,*=,/=, easy increment and decrement with variable++ and variable--, and more. You can work with different numerical bases and even convert from one number base to another. For example, here are the answers to what 100 octal (base 8) and 101010101010101010 binary (base 2) are in decimal:
echo $((8#100))
echo $((2#101010101010101010)
The way it interprets quote characters
The shell recognizes four different types of quote characters:
- The single quote character '
- The double quote character "
- The backslash character \
- The back quote character `
The first two and the last characters in the preceding list must occr in pairs, while the backslash character can be used any number of times in a command as needed.
The Single Quote
Enclose the entire argument inside a pair of single quotes, to pass arguments that include whitespace characters to programs. When the shell sees the first single quote, it ignores any special characters that follo until it sees the matching closing quote.
Quotes are also needed when assigning values containing whitespace or special characters to shell variables, though there are nuances.
The Double Quote
Double quotes work similarly to single quotes, except they’re less protective of their content: single quotes tell the shell to ignore all enclosed characters, double quotes say to ignore most. In particular, the following three characters are not ignored inside double quotes:
- Dollar signs,
- Back quotes,
- Backslashes.
The fact that dollar signs are not ignored means that variable name substitution is done by the shell inside double quotes.
Where this gets a bit weird is that double quotes can be used to hide single quotes from the shell, and vice versa.
The Backslash
Functionally, the backslash (used as prefix) is equivalent to placing single quotes around a single character, though with a few minor exceptions. The backslash escapes the character that immediately follows it.
end
intro file content:
The Unix operating system was pioneered by Ken Thompson and Dennis Ritchie at Bell Laboratories
in the late 1960s . One of the primary goals in
the design of the Unix system was to create an environment that promoted efficient program development.
-11 22333 44
22- ssss-
phonebook file content:
Alice Chebba 973-555-2015
Barbara Swingle 201-555-9257
Liz Stachiw 212-555-2298
Susan Goldberg 201-555-7776
Tony Iannino 973-555-1295